Tour de App není algoritmická olympiáda, kde se dá sečíst správnost a rychlost. My děláme simulaci reálného vývoje – a hodnocení je nástroj, který tu simulaci drží pohromadě.
V praxi pořád balancuješ tři pohledy, jak oceňovat odevzdaná řešení (v některých případech se shodují, někdy je to spíše trade-off):
- IT pohled (hard) – je to technicky správně, bezpečné, stabilní, maintainable?
- Klientský pohled (value) – řeší to potřebu, dává to smysl pro uživatele, jak moc je to „hotový produkt“ a ne jenom demo?
- Vzdělavatelský pohled (growth) – posune to tým? Dostanou , podle kterého udělají další krok lépe a něco se naučí?
Pozn.: Z interního šetření napříč TdA25 vylezlo, že se na tomhle poměru (zejména IT vs Klient) neshodneme. A to je v pořádku – pointa je ty tři směry vědomě namíchat a nenechat to náhodě.
Zohlednění projektového řízení
Máme tu další otevřenou otázku do budoucích ročníků: Jak moc chceme, aby se v hodnocení propsalo řízení projektu a komunikace, aniž bychom z toho udělali soutěž v povídání?
Persóny hodnocení
IT hodnotitel
Náš vnitřní ajťák hlídá:
- shodu s API specifikací a core požadavky,
- bezpečnostní průšvihy (aspoň ty nejkřiklavější),
- stabilitu, edge-cases, validaci,
- základní maintainability projektu (struktura, rozumné technologie).
Klient
Klientský pohled není o tom, že „klient ví, co chce“. Je to o tom, že v reálu musíš umět:
- vyčíst potřebu z neúplných/zmatených informací,
- zpřesnit požadavek (ptát se, ověřovat si, validovat teorie),
- dodat řešení, které dává smysl i někomu mimo tvůj tým.
Tady se opíráme o úplně běžnou realitu requirements engineeringu – práce se stakeholdery, analýza, záznam a validace požadavků.
Vzdělavatel
Tahle persóna hlídá, aby hodnocení bylo zároveň i :
- feedback je pochopitelný i ve stresující situaci spojené s vyhlašováním (a možná ani není spojený se skóre),
- vede k dalšímu kroku („tak teď se musí líp naučit...“),
- nesklouzává do moralizování nebo „tady máte 0, čau“.
A ano – sem patří, protože pracovní svět je reálně vyžaduje.
Hodnocené kategorie
V každé fázi soutěže se typicky díváme na dvě hlavní věci:
- FX (Funkční část aplikace) – co aplikace umí a jestli to dělá správně
- UX (Design a uživatelský zážitek) – jak se to používá a jestli to dává smysl uživateli
V Nominačním kole pak přidáváme ještě:
- AT (Automatické testy) – průběžná kontrola, jestli se dodržují např. specifikace API
Pomůcka:
FX bez UX vyrobí „funguje to, ale nikdo to nechce“.
UX bez FX vyrobí „krásná prázdná skořápka“.
AT (Automatické testy)
Automatické testy jsou aktuálně specialitou Nominačního kola. Hlavním znakem by mělo být, že pokrývají 100% OpenAPI/Swagger specifikace (a případně dalších technických specifikací, zejména na straně backendu). Tím je nejvíce ukojena persóna IT hodnotitele.
- Organizačně nám dovolují soutěž v Nominačním kole jednoduše napříč mnoha týmy.
- Didakticky dává týmům rychlou zpětnou vazbu, jestli jsou na správné koleji.
- Simulace reality – přesná API specifikace může být legitimní požadavek klienta (a v korporátu to fakt existuje, viz Contract testing).
Automatické testy v Soutěžním kole?
Ačkoliv je jedním z SK nechat týmy navrhovat vlastní kreativní řešení, stále může být žádoucí nechat jim možnost průběžné kotroly jejich implementace skrze AT. Pozor ale na to, aby dodržování specifikace neukrajovalo z požadované kreativity.
Obsah a struktura testů
Automatické testy nemusí nutně pokrývat 100% coverage OpenAPI/Swagger specifikace pro definované endpoints, ale měly by:
- testovat základní žádoucí chování i nežádoucí chování (validace vstupů, chybové stavy, návratové kódy),
- být rozdělené do fází, přičemž s každou další fází se zvyšuje obtížnost a zároveň fáze odpovídají pravděpodobnému progresu vývoje (např. nejprve CRUD jedné položky eshopu až v další fázi kontrola funkce vyhledávání s filtry),
- přičemž každá fáze by měla být rozdělena do většího množství malých testů s návaznostmi (Delete pouze pokud funguje Create) a s explicitním pojmenováváním případných nesrovnalostí (e.g. Update failed because you are missing required field UUID).
TdA26: Testy psané pomocí AI
Automatické testy psané rychle přes AI bez lidské kontroly jsou průšvih. AI si ráda vymyslí:
- povinnosti/nepovinnosti polí,
- formáty,
- návratové kódy... a pak trestáš týmy za něco, co není ve specifikaci.
Poučení: Testy musí projít review stejně přísně jako zadání - ať se na to kouknou minimálně dva lidi.
Transparentnost testů
Tým by měl mít přístup ke kódu testů, ale zároveň schovat takové části, které by umožnily hardcoded implementace na test data. Zároveň by testy měly být lidsky čitelné, tedy jasně říct co je testované, co je netestované, případně co je pouze doporučení.
Výstup testů musí být „lidsky čitelný“
Realita: překvapivě hodně týmů neumí číst error output. Takže testy musí:
- padat srozumitelně (co přesně nesedí),
- ideálně ukázat diff (očekávané vs. skutečné),
- nehavarovat na prvním prdu (robustní diagnostika).
Interpretace automatických testů pomocí AI
Do budoucna se nabízí otázka, zda a jak zapojit AI jako „překladač“ výstupů automatických testů do srozumitelné lidské řeči – tedy formou shrnutí výsledků, identifikace typických chyb a návrhu dalšího rozumného kroku. Jde o jeden z mála AI use-casů, kde dává smysl a nenarušuje férovost soutěže, pokud AI pracuje výhradně s interpretací existujících logů a nepřidává nové rady nad rámec dat.
Žádný chatbot, ale zkrátka malý textový hint.
Inkrementální testování (proč a jak)
Historická zkušenost z TdA23 a dříve ukazuje, že přístup „tady máte všechny testy“ funguje jako zeď, přes kterou slabší týmy neprojdou. Díky přidání inkrementálního odevzdávání s postupným testováním jsme dosáhli toho, že se víc týmů chytí, mají rytmus, vidí svůj progres.
Co hlídat, aby tento princip fungoval i nadále?
- Inkrementy mají kopírovat rozumný vývoj (nejdřív core funkce, pak edgecases a nice-to-haves).
- Nepřidávej testy s variabilní obtížností – to opět jen frustruje týmy.
FX (Funkční část aplikace)
FX je odpověď na otázku: „Když si představím reálného uživatele, dokáže v té aplikaci udělat to, co má?“
FX je zároveň místo, kde se nejvíc hádají naše persóny:
- IT chce konzistenci, validaci, edge-cases, bezpečnostní minimum.
- Klient chce, aby to dávalo smysl a šlo to používat jako produkt, ne jako demo.
- Vzdělavatel chce, aby FX ohalilo nejčastější (hloupé) prohřešky a týmy se zkrze feedback naučili, co dělat příště jinak.
Aby to nebyla soutěž ve filosofii, držíme FX hlavně skrze pevně definované scénáře.
FX Scénáře
Testovací scénáře mají být formulované jako uživatelské úkoly reprezentující reálné situace, které uživatel v aplikaci vykoná (např. vytvoření objednávky, úprava profilu, odeslání formuláře).
Scénáře jsou nezávislé na implementaci – popisují „co“ a „proč“, ne „jak“.
Barevná rozšíření
Dříve (TdA23) byly scénáře definované jako barevné skupiny různých rozšíření, které byly povinně volitelné. To ale nesimulovalo reálného klienta a nutilo to týmy optimalizovat pro největší bodový zisk.
Příklad scénáře (e-shop):
- „Jako zákazník chci přidat 2 kusy produktu do košíku, upravit množství na 1 a objednávku dokončit.“
- V detailu to pak vede na pod-scénáře: práce se stavem košíku, validace vstupů, chybové stavy, persistence, výpočet ceny, …
TdA25: Chybějící návaznosti mezi scénáři
V TdA25 jsme zaváděli ŠpehFish, což bylo webové rozhraní, které náhodně přidělovalo testované aplikace a provedlo uživatele všemi testovacími scénáři. Problém nastal v momentě, kdy nebyla implementována funkce Vytvoř XX. Následující scénáře (Uprav XX, Smaž XX) tak nedávaly smysl a bylo to HODNĚ zbytečného klikání navíc.
Poučení: Scénáře jsou navzájem provázané (občas i komplexním způsobem typu (A && B) || C). Pokus se minilazovat vznik zanedbaných logických návazností.
Časté chyby (persona vzdělavatel)
Scénáře mají pokrýt i typické prohřešky začátečníků – a dneska hlavně týmů, které vše tvoří s AI bez kontroly:
- „funguje to jen na happy-path“ (žádné chyby, žádná validace),
- „UI říká OK i když server padá“ (neřeší se chybové stavy, timeouty, chybové hlášky),
- „data se ztratí po refreshi stránky“ (nebo se uloží špatně),
- „security by vibes“ (neautorizované akce, základní XSS/IDOR průšvihy).
Když tým narazí na konkrétní fail ve scénáři, je to vzdělávací moment. Je lepší jim říct „tady máte konkrétní díru“ místo „máte to špatně“.
Prioritizace (persona klient)
Ne všechny scénáře mají stejnou hodnotu. Bodově (a mentálně) je vážíme podle:
- byznys dopadu (co je důležitá funkce?),
- rizika (kde je průšvih nejdražší?),
- frekvence (co se děje pořád a co jen zřídka?),
- reputace (odežene to uživatele hned jako první věc na stránce?).
Takže třeba přihlášení a nákup produktu bývají „tvrdší“ než administrace uživatelského profilu.
Pozitivní i negativní scénáře (persona IT)
Scénáře musí popisovat:
- správné chování (happy-path),
- chybové stavy (invalid input, missing data, duplicity, neexistující zdroj, konflikt),
- autorizaci (kdo to smí dělat).
Tým, který zvládá jen happy-path, má hotové demo. Ne produkt.
CAT – Contract Acceptance Testing
V reálu existuje moment „posledního checkpoint“, kdy se ověřuje, že dodávka odpovídá dohodnutým požadavkům.
V TdA se tomu nejvíc blíží naše finální ověření FX vůči zadání – něco jako Contract Acceptance Testing.
Je to další ze způsobů, jak se přiblížit realitě.
UX (Design a uživatelský zážitek)
I perfektně funkční appka může být nepoužitelná – a naopak krásná appka může být jen prázdná skořápka.
Ale existují ověřené principy, které se dají přeložit do poměrně objektivních kontrolních bodů. Je to kompromis, kterým chceme posunout diskusi z „líbí–nelíbí“ na „proč to (ne)funguje“.
UX/UI principy
Existuje několik metodologických přístupů, jak se díváme na UX/UI, ale aby výstupem bylo objektivní bodové ohodnocení, využíváme zejména heuristické hodnocení (systematické procházení checklistu definovaných principů).
Definování „nejlpeších“ heuristik
Hodnocení UX/UI aspektů je v TdA hodně proměnlivé, což naznačuje, že by mělo být i nadále iterováno.
Existuje několik průmyslových standardů pro heuristické hodnocení, jeden z nejpopulárnějších je 10 heuristik Jakoba Nielsena. Přeloženo do praxe to znamená, že hodnotitel nekouká jen na estetiku, ale ptá se třeba:
- Ví uživatel, co se právě děje? (viditelnost stavu systému)
- Mluví rozhraní jazykem člověka, nebo jazykem vývojáře? (match se skutečným světem)
- Má uživatel možnost „undo“ a úniku z průšvihu? (kontrola a svoboda)
- Je to konzistentní? (standardy)
- Brání UI chybám, nebo je vyrábí? (prevence chyb)
- Nemusí si uživatel pamatovat zbytečnosti? (recognition > recall)
- Je to efektivní pro zkušenější uživatele? (flexibilita)
- Není to přeplácané? (minimalismus)
- Když nastane chyba, umí ji uživatel pochopit a opravit? (recover)
- Existuje pomoc a dokumentace, když je potřeba? (help)
Druhá známá sada pravidel, která stojí za zmínku, je Shneidermanových 8 zlatých pravidel .
Zajímavé otázky, které si položit:
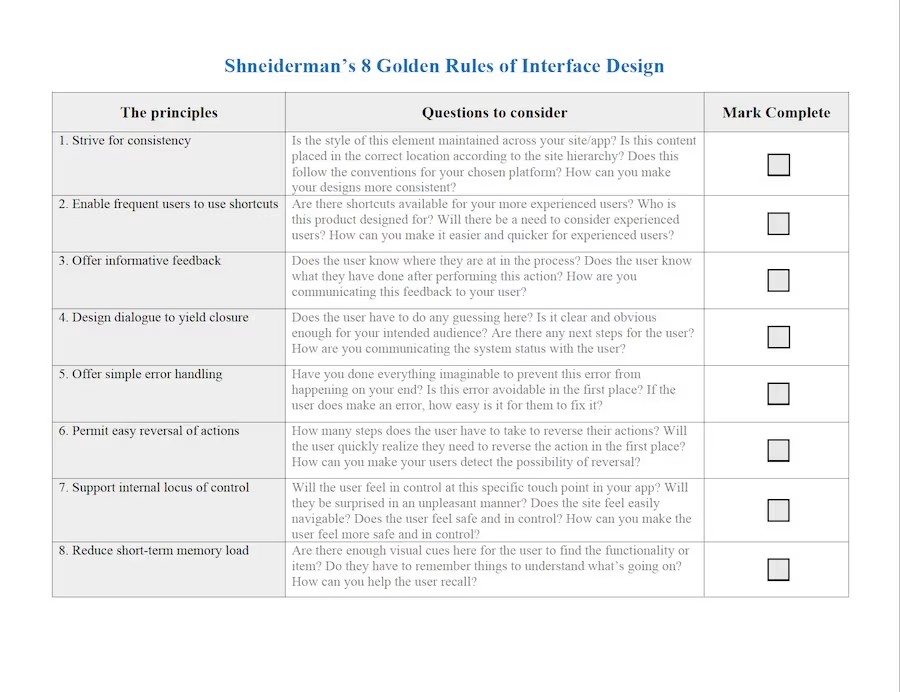
A existuje mnoho dalších principů použitelnosti, jako základ ale doporučuji zkopírovat loňskou hodnotící matici, revidovat ji svým kritickým očkem, psát si případné poznámky a revidovat jakmile ji budeš mít pod kůží.
Heuristic evaluation jako metoda
Heuristická evaluace je metoda, kdy aplikaci prochází skupina expertů, která aplikaci zkoumá podle předem stanovených principů tak, aby našli typické problémy. Jako proces je to hezky popsané tady.
Prakticky v TdA:
- hodnotitel(é) má checklist/škálu odvozenou z heuristik
- a u každého nálezu si uvědomuje „problém → dopad → míra závažnosti“.
Refactoring UI
Refactoring UI je výborná kniha, protože bere „design vibes“ a dává jim konkrétní příklady: vizuální hierarchie, spacing, kontrast, konzistence komponent, feedback. Až do teď jsem se tu bavil zejména o UX, protože UI se hodnotí ještě hůře a častokrát je pro hodnotitele problém tyto dvě kategorie oddělit. Existují však konkrétní UI-specific heuristiky, které zahrnujeme, abychom něco neopomenuli.
Doporučuju se podívat v online verzi alespoň na rejstřík kapitol, dají se z toho vytáhnout hezké příklady.
Kategorie a přidělení váhy
Jakmile rozdělíš hodnocení do kategorií a podkategorií, narazíš na problém:
kategorie s více položkami začne nefér dominovat, i když není nutně důležitější.
Proto oddělujeme důležitost kategorie od její granularitiy.
Základní princip:
- každá hlavní kategorie má ručně danou váhu (na základě dohody persón/týmu),
- počet podpoložek váhu nezesiluje lineárně,
- místo toho se jejich vliv tlumí (např. odmocninou).
Používaný model odpovídá běžným weighted scoring / MCDA přístupům: váhy se kombinují tak, aby žádné kritérium nedomninovalo jen proto, že je „víc rozepsané“.
Formálně:
kde:
- výsledkem je normalizovaná (unbiased) váha kategorie.
Uvnitř kategorie se pak její váha dál rozdělí mezi podpoložky tak, aby daly 100 %.
Jak k téhle magii Víťa došel?
- více položek ≠ vyšší důležitost,
- hodnotíš význam, ne počet checkboxů,
- model je obhajitelný, ale pořád praktický.
GRF: Prezentace výsledků
Druhá část Grandfinále (GRF) je zaměřena na prezentaci výsledného řešení před porotou, která zde vystupuje v roli stakeholderů. Tato část neslouží pouze k demonstraci funkčnosti aplikace, ale především k posouzení schopnosti týmu , a hlavně .
V závěrečné fázi soutěže se týmy často dostávají do situace, kdy jsou jejich řešení z hlediska funkční implementace velmi vyrovnané. Rozdíly v architektuře, použitých technologiích nebo dílčích detailech bývají pro externího hodnotitele obtížně objektivně porovnatelné. Tento jev je dobře popsaný i v odborné literatuře zabývající se hodnocením hackathonů – technická kvalita se v pokročilých fázích soutěže stává nutnou, nikoli postačující podmínkou úspěchu.
Pitch slouží jako nástroj, který umožňuje:
- odhalit porozumění problému, nikoli jen jeho implementaci,
- zhodnotit, zda tým dokáže přemýšlet produktově, nikoli pouze technicky,
- posoudit schopnost rozhodování pod tlakem, což je klíčová dovednost v reálných projektech.
V reálném světě je MVP hodnoceno primárně podle toho, zda dokáže přesvědčit investory, zákazníky nebo vedení organizace, nikoli podle elegance kódu.
Bohužel se zde nemůžeme bavit o přesných kritériích, ale vše závisí na kvalitním !